Documentation Index
Fetch the complete documentation index at: https://docs.semilattice.ai/llms.txt
Use this file to discover all available pages before exploring further.
We are working with early partners to build custom user models from unstructured data. Learn more →
Requirements
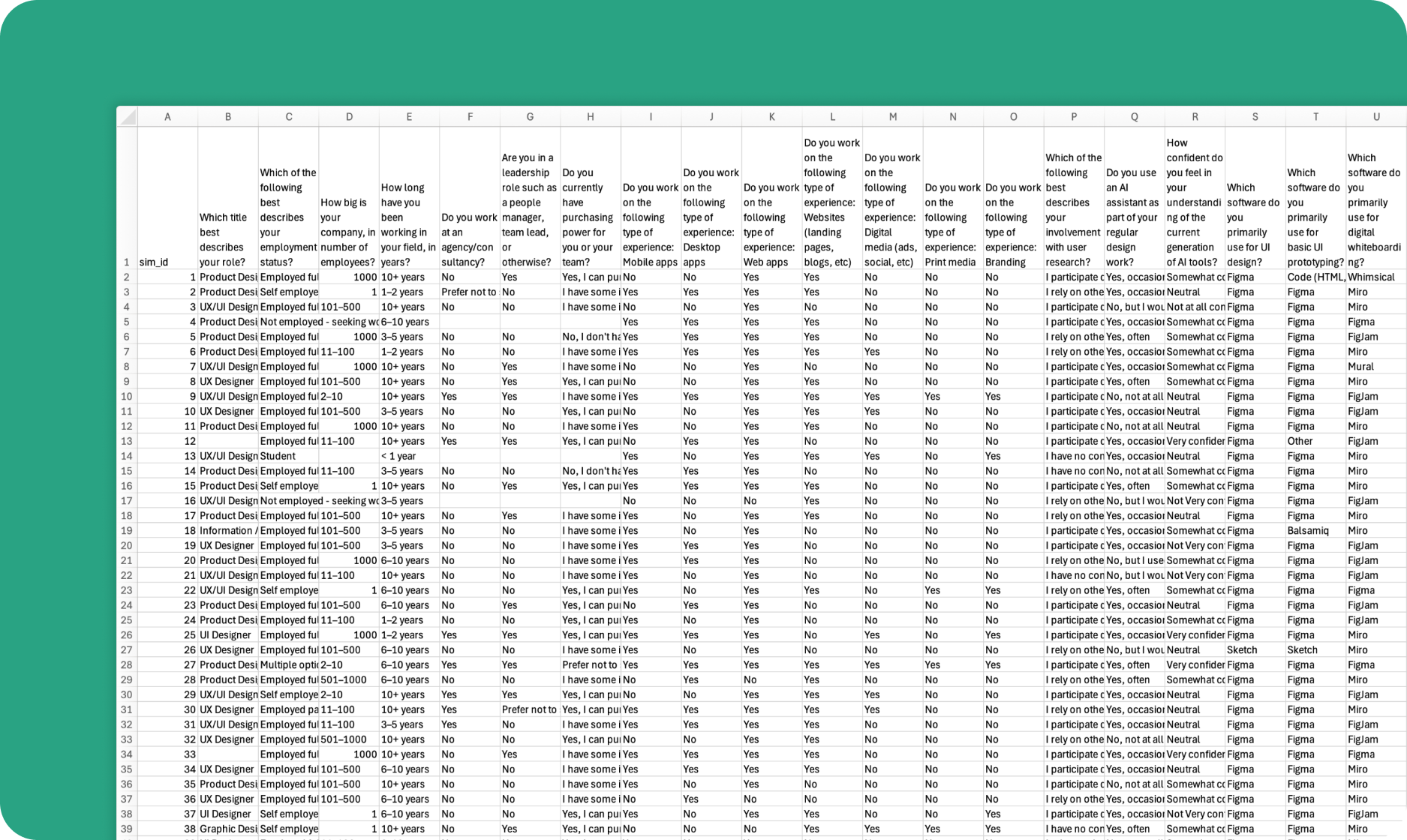
Populations require tabular, individual-level question-answer pair data from the group of people the population aims to model. For example: data from a survey, poll, questionnaire, or onboarding form where each row is an individual’s answers to a set of questions.Question types
The API supports three question types in seed datasets:- single-choice: individuals choose a single answer from a finite list of options.
- multiple-choice: individuals choose multiple answers from a finite list of options, sometimes with a limit on the number of options they can choose.
- open-ended: individuals answer in their own words.
Technical requirements
The API accepts.csv files which meet the following requirements:
- the first column must be titled sim_id
- the sim_id column should contain a unique number in each row
- there should be between 4 and 999 question columns
- questions must be between 3 and 999 characters long
- there should be between 1 and 99,999 respondent rows
- answer cells can be empty
- non-empty answers must be no more than 999 characters long
- answers cannot contain newline characters
- there must be at least one single-choice or multiple-choice question column in your seed data file because open-ended questions cannot be tested
- for single-choice and multiple-choice questions, there should be between 1 and 500 unique answer choices
- non-empty answer cells for single-choice and open-ended questions must be valid strings representing the respondent’s answer e.g. “Somewhat Agree” or “I usually go to the beach”
- non-empty answer cells for multiple-choice questions must be valid lists of quoted strings representing the respondent’s set of answer choices e.g. ”[‘Chocolate’, ‘Vanilla’, ‘Lemon sorbet’]”
While the API supports very small and very large datasets, due to the availability of ground truth data most of our modelling and benchmarking work to date was done with datasets containing ~5-20 questions from ~50-3,000 respondents with fewer than 5% empty cells. Dataset size is a modelling decision and we encourage experimentation by running population tests and benchmark simulations to find the best subset for your goals.
Example
This very small CSV is valid, containing answers to 4 questions from 10 respondents. The first two question columns are single-choice questions, the third is multiple-choice, and the fourth is open-ended.Qualitative requirements & guidelines
The API doesn’t check if your seed data follows these requirements and guidelines, but they are essential to creating effective populations.Column headers should be questions or propositions
Column headers should be questions or propositions
Semilattice assumes column headers are questions or propositions: pieces of text posed to people who can respond with an answer. For example, “What is your favourite colour?” is a question while “You believe reality is…” is a proposition.
Questions cannot assume knowledge of other questions
Questions cannot assume knowledge of other questions
Questions can’t assume the responder has any knowledge of the other questions in the dataset. For example, the question “How strongly do you feel about your answer to the last question?” will not work because with simulated respondents there isn’t an equivalent of a last question.
Answer options cannot refer to other answer options
Answer options cannot refer to other answer options
Answer options cannot refer to the question’s other answer options. For example, the answer option “None of the above” is invalid because its meaning depends on the other answer options. However, “None” is valid as its meaning is independent.
Questions and answer options must be human-readable
Questions and answer options must be human-readable
Question-answer pair datasets often record questions and answers as descriptors, identifiers, or codes requiring lookup in data dictionaries. Semilattice only accept a single
.csv, so questions and answers have to be decoded into human-readable values.All questions and answers should come from the same source such as a single survey, questionnaire, or onboarding form
All questions and answers should come from the same source such as a single survey, questionnaire, or onboarding form
Mixing data from different samples is not recommended. Semilattice assumes seed data come from a source.
Answers in a row should all come from the same person
Answers in a row should all come from the same person
Mixing answers from different people is not recommended. Semilattice assumes all the answers in a row come from the same person.
Good to know
These considerations are useful to bear in mind.Other types of questions can be reformatted to be compatible, with caution
Other types of questions can be reformatted to be compatible, with caution
Questions which were originally posed as single-choice, multiple-choice, or open-ended questions are recommended, but if necessary other types of questions can be reformatted to meet the technical requirements. Caution is advised though: the more you reformat, the more your seed data will diverge from reality.
Question order doesn't matter
Question order doesn't matter
The order of the question columns in your seed data has no effect. Questions will be used in various ways, in various orders.
Answer option order is always random
Answer option order is always random
Answer options will be presented in random order by default. Answer options with semantic order (e.g. “Strongly Agree” to “Strongly Disagree”) are perfectly valid, but answer options which assume an order (e.g. “None of the above”) are not. Answer options like “None of the above” should be reformatted to stand alone, e.g. “None”.
Bigger datasets can be filtered, with caution
Bigger datasets can be filtered, with caution
You can filter large datasets down to specific segments, subsets of questions, or the right number of respondents for Semilattice. However, just like with a real-world dataset, heavy filtering can reduce the quality of the resultant sample and can lead to lower accuracy population models.
Seed data are not the only data
A population’s seed data do not represent all of the information which Semilattice uses to make predictions. Most of the information comes from the Large Language Model (LLM) used by the Simulation Engine, with the seed data effectively selecting the relevant information from the LLM. This means that you should think about the predictive power of the questions and answers in the seed data rather than the actual information contained in those questions.Predictive power
A population’s accuracy when predicting the answer to a new question is dependent on the predictive power of the questions and answers in its seed data. This predictive power varies depending on the question being predicted and is a function of how those seed data work with the Simulation Engine.Predictive power cannot be predicted
Due to the black box nature of the LLMs used by Semilattice, it’s not yet possible to tell which seed data have more predictive power with certainty.Building intuition around predictive power
An intuitive way of estimating the predictive power of a question is to think about how informative someone’s answer to that question would be. For example, knowing someone’s age tells you a lot more about them than knowing whether they prefer ketchup or mayonnaise. However, it’s also important to consider the purpose of the population you are building. If you work in R&D at Heinz, the latter question will have more predictive power for the questions you plan to predict.Predictive power is an area of research for Semilattice. If you want to go deeper, it maps broadly to the concept of feature selection in machine learning & data mining.
Question selection best practices
The subset of questions you include in your seed dataset has the biggest impact on the accuracy and predictive reach of your population. These best practices will help you achieve the best results.Maximise predictive power
Pick questions with the most predictive power for your research objective.
Minimise subjective overlap
Pick a diverse set of questions, minimising questions which reveal similar information. For example, the questions “Do you prefer ketchup, mayonnaise, or mustard?” and “What is your favourite condiment on french fries?” have a high degree of subjective overlap.
Maximise the number of questions and responses
While not strictly required, a dataset with 20 questions and 3,000 responses is recommended. Datasets of 1,000 responses and ~10 questions can also work well.