Documentation Index
Fetch the complete documentation index at: https://docs.semilattice.ai/llms.txt
Use this file to discover all available pages before exploring further.
Testing methodologies
Semilattice uses two types of testing to evaluate population model accuracy.Built-in cross-validation
The default testing method uses a population model’s seed data to evaluate its accuracy via leave-one-out cross-validation. For each question in the seed dataset:- The question and all answer data are temporarily removed from the set of data used by the model.
- The question is then predicted using the remaining data.
- Accuracy scores are calculated by comparing the predicted answer distribution with the held back ground truth distribution.
User-defined test runs
You can also test population models against sets of ground truth questions which are not part of the seed dataset. This enables use-case specific or periodic benchmarking. See the tests section to learn how to run test predictions.Triggering cross-validation
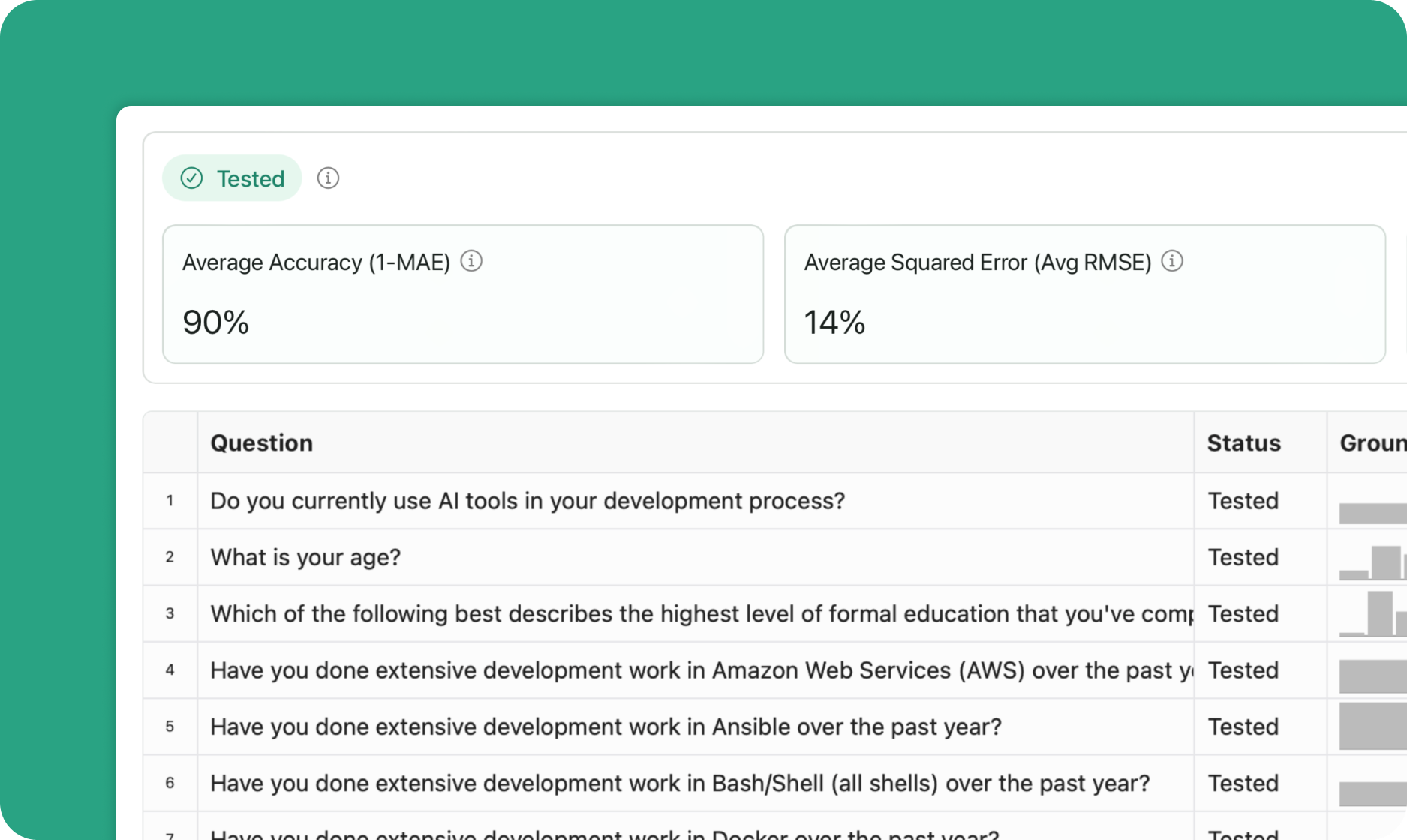
You can trigger cross-validation tests using the test method:- “Testing”: Population test is currently running
- “Tested”: Testing completed successfully, metrics are available
Evaluation metrics
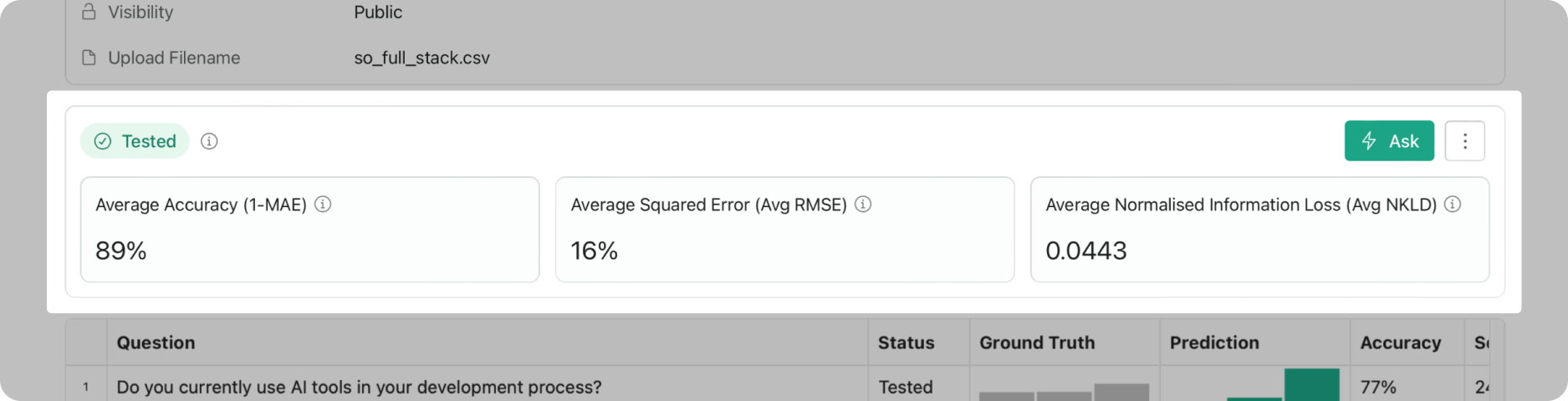
Average Accuracy
- Field:
average_accuracy - Range: 0 to 1 (higher is better)
- Calculation: The mean absolute error (MAE) between the predicted and ground truth answer distributions for each question is calculated, averaged, and then subtracted from 1 to convert it from an error measure to a crude accuracy measure.
- Example: 0.8721
Average Squared Error
- Field:
average_squared_error - Range: 0 to 1 (lower is better)
- Calculation: The root mean squared error (RMSE) between the predicted and ground truth answer distributions for each question is calculated and then averaged.
- Example: 0.1607
Average Normalised Information Loss
- Field:
average_normalised_information_loss - Range: 0 to 1+ (lower is better)
- Calculation: The Kullback–Leibler (KL) divergence (also called relative entropy) between the predicted and ground truth answer distributions for each question is calculated, normalised to the number of answer options in the question, and then averaged.
- Example: 0.0063
Interpreting results
Based on all of our benchmarking to date, we have some hueristics on what “good” looks like.Good performance thresholds
- Average Accuracy: Above 0.85 (higher values indicate better accuracy)
- Average Squared Error: Below 0.18 (lower values indicate more consistent predictions)
- Average Normalised Information Loss: Below 0.1 (lower values indicate better distribution matching)
Benchmarking context
These thresholds come from extensive benchmarking work:| Metric | Good Threshold | Benchmarking Average | Benchmarking Range |
|---|---|---|---|
| Average Accuracy | Above 0.85 | 0.87 | 0.82 - 0.92 |
| Average Squared Error | Below 0.18 | 0.16 | 0.11 - 0.24 |
| Average Normalised Information Loss | Below 0.1 | 0.0569 | 0.0244 - 0.1006 |
We increasingly find Average Normalised Information Loss to be the best single metric, but usually expect scores across all three metrics to be “good” to consider a population model reliable.